프로젝트에서 페이징이 걸려있는 상품 전체 조회 및 키워드로 검색할 시에 N + 1 문제가 발생하여 해결방법에 대해 알아보고자 한다.
현재 Goods 엔티티에서는 2개 이상의 컬렉션이 있고, 페이징이 걸려있기 때문에 fetch join으로 해결할 수 없어 batch size를 통한 방법을 알아보았다. 뿐만 아니라 N+1 문제의 원인 , 해결방법에 대해 학습한 내용을 정리하려고 한다.
N+1 문제로 인해 대량의 데이터가 있는 애플리케이션이 아니라면 성능에 상관없이는 그냥 지나칠 수 있는 문제이지만,성능 개선을 위해서는 필요한 지식이라고 생각한다.
학습하면서 생각해보았다.상황에 맞추어 적절한 방법을 선택해야겠지만, 지연로딩은 필수로 사용하며 페이징과 List 컬렉션을 사용해야 한다면 Batch Size 를 사용하는 것이 베스트가 아닐까 생각된다.
먼저 JPA 에서 발생하는 N + 1문제란,
연관 관계가 설정된 엔티티를 조회할 때 발생하며, 조회된 데이터의 개수 만큼 조회 쿼리가 추가로 나가는 것을 의미한다.
fetch 전략을 EAGER (즉시로딩)을 사용하게 되면 연관되어 있는 객체의 정보를 다같이 조회하게 된다.
한 번에 다같이 조회하면 편하기만 할거같은데, 왜 문제가 될까??
JpaRepository 를 상속한 Repository 는 findById , findAll 등 다양한 메서드를 자동으로 제공해준다.
이 메서드들을 사용할 때는 jpql 을 내부적으로 만들어져서 나가는데 이것이 문제가 된다.
findById 처럼 단일조회를 하는 쿼리가 날아가면, JPA 가 내부적으로 join 을 사용해 최적화를 진행한다.
하지만 findAll 을 사용하게 되면, " select m from Member m " 의 쿼리(1개)가 나가게 되는데, EAGER 로 되어있다면 모든 유저와 연관되어있는 정보를 모두 찾는 쿼리(N)가 날라가게 된다.
EX ) 유저A 가 a,b,c,d,e 게시글을 가지고 있고, 유저 B가 f,g,h,i,j 의 게시글을 가지고 있다면 N+1 문제가 발생한다.
그 수가 커지면 커질수록 N+1 문제의 심각성은 커진다.
따라서, 즉시로딩은 jpql로 전달되는 과정에서 즉시로딩 감지로 인해 추가 쿼리가 발생할 경우가 있으므로 사용하지 않는다.
그러면 어떤 것을 사용해야할까? LAZY 지연로딩을 사용하면 된다.
다만, 지연로딩을 사용한다고 해서 완벽히 해결되는 것은 아니다.
지연로딩은 연관된 객체를 사용하는 시점에 로딩을 해주는 방법이다.
처음 find 할때는 N+1 문제가 발생하지 않지만, 지연로딩 대상은 프록시객체로 임시 저장되며 이후 연관된 객체를 사용할때 N+1 쿼리 문제가 발생할 수 있다.
즉시로딩에서는 더 이상 커스텀할 부분이 존재하지 않아, 즉시로딩에서 fetch join 을 이용하여 문제를 해결 할 수 있다.
일반적인 jpql 로 커스텀해 준다고해서 N+1 문제를 해결 할 수 없다.
@Query("select distinct m from Member m left join m.board")
List<Member> findAllJpql();이유는 join 을 했어도 프록시로 가져오는 것은 변하지 않기 때문이다.
fetch join을 사용하면 지연로딩이 걸려있는 연관관계에서 한번에 같이 즉시로딩을 해준다.
@Query("select distinct m from Member m left join fetch m.board")
List<Member> findAllFetchJoin();fetch join을 대체하는 방법은 @EntityGraph 가 있는데 사용법은 아래와 같다.
@EntityGraph(attributePaths= {"borad"}, type= EntityGraphType.FETCH)
@Query("select distinct m from Member m left join m.board")
List<Member> findAllEntityGraph();
fetch join 은 문제점을 가지고 있다.
N+1 문제점은 해결할 수 있지만 Page(페이징) 기능에서는 사용할 수 없다.
하이버 네이트에서는 왜 fetch join 과 페이징기능을 동시에 사용할 수 없게 해놓았을까??
관계형 DB 에서는 join 쿼리가 발생하게 되면 N 의 개수만큼 데이터가 발생한다. ( 뻥튀기 )
ex ) 주문 A 에 itemA , itemB 가 있고 , 주문 B 에 ItemC 와 ItemD 가 있을 때, join 을 실행한 쿼리를 날리면 결과가 4개가 나타난다.
1. 주문A - itemA
2. 주문A - itemB
3. 주문B - itemC
4. 주문B - itemD
우리가 기대한 Order의 개수는 2개인데 결과상으로는 4개가 발생한 것이다.
위의 상태에서 페이징으로 2개씩 가져와달라고하면 주문 1,2 번만 가지고 온다.
결과적으로는 우리가 기대한 값과 다르게 페이징처리를 해버리게 된다.
Mysql 에서 페이징처리를 할때 쿼리에서 볼 수 있는 limit 과 offset 이 출력되지 않는다.
페이징의 존재 이유가 없어지면서 데이터가 굉장히 많다면 Out of Memory 가 발생할 수 있다.
또한, 2개 이상의 컬렉션 타입 은 fetch join을 사용할 수 없다.
페이징의 해결책은 Batch Size를 사용하는 것이다.
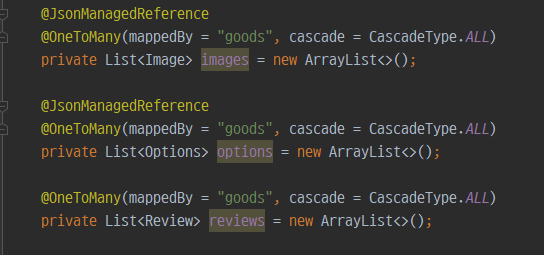

현재 내 프로젝트의 N+1 현상을 보면 아래와 같다.
페이징을 이용해서 10개를 조회했는데 N+1 문제가 발생했다.

위의 정리한 내용처럼 나는 컬렉션타입(List) 를 2개이상 사용하고 있으면서, 페이징기능을 사용하고 있기 때문에
Batch Size를 이용했으며, 쿼리가 발생하는 양이 줄었고 메서드 실행시간 또한 확연히 차이가 났다.
Batch Size 의 설정만큼 나누어서 쿼리를 날려준다
ex) 100으로 설정했는데 데이터가 150개면 1~100 / 101~150
size 는 In 쿼리를 몇개씩 설정한건지에 대한 것인데, 너무 높게 설정하면 부하가 걸릴 수 있고 너무 작게하면
쿼리가 많이 생성되어 사용하는 효과가 미비하다.
따라서, 환경에 맞는 설정이 필요하다
또한, batch size 의 설정에 따라서 네트워크 상의 데이터를 주고받는 속도에만 영향이 있고 메모리에는 영향을 주지 않는다.
이유는 1000개의 데이터를 가지고 올때 size가 100 이든 1000 이든 가져오는 데이터의 개수는 같기 때문에 영향이 없다.
yml 에서 Batch Size 를 설정해주었다.
jpa:
properties:
hibernate:
default_batch_fetch_size: 100
쿼리를 자세히 보면 Batch size를 설정 안한 쿼리는 where 절을 사용하고 있으면서 1개씩 찾아와야 하기 때문에 ? 가 하나만 붙어있다.

Batch Szie를 설정한 쿼리에는 where 대신 하나의 in 으로 쿼리가 생성된다.

참고
JPA 모든 N+1 발생 케이스과 해결책
N+1이 발생하는 모든 케이스 (즉시로딩, 지연로딩)에서의 해결책과 그 해결책에서의 문제를 해결하는 방법에 대해 이야기 하려합니다 😀
velog.io
'Spring > JPA' 카테고리의 다른 글
| QueryDsl 설정 방법 - Spring boot 2.7.x (1) | 2023.02.03 |
|---|---|
| List 타입을 Page 타입으로 리팩토링 (0) | 2023.01.28 |
| @Convert - T타입 + Map 사용하기 (0) | 2023.01.14 |
| JpaRepository 와 CrudRepository 의 차이점 (0) | 2022.12.04 |
| JPA 순환 참조 해결해보기 (0) | 2022.11.30 |



댓글